Central VA traffic analysis
This is a simple analysis of Tweets from @511centralva to analyze traffic conditions in the Central VA area. The is the first attempt without any NLP and utilizes regex to parse tweets.
The aim is to obtain accident prone zones and times during the day.
import tweepy
import pandas as pd
pd.set_option('display.max_colwidth', 146)
from matplotlib import pyplot as plt
from datetime import datetime as dt
import pickle
at = lambda :dt.now().strftime("%Y%m%d%H%M")
at()
'201711161853'
consumer_key = 'YOUR CONSUMER KEY HERE'
consumer_secret = 'YOUR CONSUMER SECRET HERE'
access_token = 'YOUR ACCESS TOKEN'
access_token_secret = 'YOUR TOKEN SECRET'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
Get all tweets from 511 Central VA as of 18:50pm Nov 16
js = api.user_timeline('511centralva')
len(js)
20
while True:
temp = api.user_timeline('511centralva', count=200, max_id=js[-1]._json['id'])
if js[-1]._json['id'] == temp[-1]._json['id']:
break
else:
js += temp
len(js), js[-1]._json['id']
(3267, 923533267948720128)
Save the tweets for future use
fname = 'data_' + at()+ '.pkl'
with open(fname , 'wb') as f:
# Pickle the 'data' dictionary using the highest protocol available.
pickle.dump(js, f, pickle.HIGHEST_PROTOCOL)
Get old tweets for analysis
## reading back
with open('data_201710141356.pkl', 'rb') as f:
# The protocol version used is detected automatically, so we do not
# have to specify it.
older = pickle.load(f)
len(older)
3251
Read the tweets into a pandas dataframe for analysis
js_dict = {
'id': [_.id for _ in older],
'screen_name': [ _.user.screen_name for _ in older],
'created_at': [_.created_at for _ in older],
'text': [_.text for _ in older]
}
olddf = pd.DataFrame(js_dict)
olddf.head()
| created_at | id | screen_name | text | |
|---|---|---|---|---|
| 0 | 2017-10-14 17:30:26 | 919254082661044224 | 511centralva | Cleared: Accident: NB on US-17 (George Washington Memorial Hwy) in Gloucester Co.1:30PM |
| 1 | 2017-10-14 17:28:25 | 919253572272971776 | 511centralva | Cleared: Incident: NB on I-95 at MM53 in Colonial Heights.1:28PM |
| 2 | 2017-10-14 17:20:18 | 919251531861512193 | 511centralva | Cleared: Incident: NB on I-195 at MM2 in Richmond.1:20PM |
| 3 | 2017-10-14 17:18:25 | 919251057817083904 | 511centralva | Cleared: Incident: SB on I-295 at MM14 in Chesterfield Co.1:18PM |
| 4 | 2017-10-14 17:14:24 | 919250044829782017 | 511centralva | Incident: NB on I-195 at MM2 in Richmond. No lanes closed.1:14PM |
js_dict = {
'id': [_.id for _ in js],
'screen_name': [ _.user.screen_name for _ in js],
'created_at': [_.created_at for _ in js],
'text': [_.text for _ in js]
}
data = pd.DataFrame(js_dict)
data.head()
| created_at | id | screen_name | text | |
|---|---|---|---|---|
| 0 | 2017-11-16 23:52:20 | 931308990599979008 | 511centralva | Accident: SB on I-95 at MM75 in Richmond. Right shoulder closed.6:52PM |
| 1 | 2017-11-16 23:52:20 | 931308988968214528 | 511centralva | Update: Accident: SB on US-17 at MM112 in Essex Co. No lanes closed.6:52PM |
| 2 | 2017-11-16 23:52:20 | 931308987340992517 | 511centralva | Disabled Vehicle: SB on I-95 at MM75 in Richmond. No lanes closed.6:52PM |
| 3 | 2017-11-16 23:52:19 | 931308985784946688 | 511centralva | Cleared: Accident: NB on US-17 at MM119 in Essex Co.6:52PM |
| 4 | 2017-11-16 23:50:26 | 931308511312666625 | 511centralva | Cleared: Disabled Vehicle: WB on I-64 at MM218 in New Kent Co.6:50PM |
Perform some EDA
What is the frequency of different kinds of tweets?
data.text.map(lambda x: x.split(':')[0]).value_counts()
Cleared 1252
Update 756
Accident 714
Incident 237
Disabled Vehicle 111
Advisory 58
bridge opening 57
utility work 18
Delay 17
Vehicle Fire 15
Disabled Tractor Trailer 13
brush fire 4
maintenance 3
special event 3
signal installation 2
bridge inspection 2
Closed 1
paving operations 1
bridge work 1
road widening work 1
patching 1
Name: text, dtype: int64
len(olddf.append(data))
dummy = pd.concat([data, olddf], ignore_index=True)
dummy = dummy.drop_duplicates('id')
len(dummy), dummy.index.has_duplicates
(6484, False)
Analyze the structure of tweets
The tweets’ key elements appear to be separated by ‘:’ so lets check what is the distribution of that split.
dummy['col_cnt'] = dummy.text.map(lambda x:len(x.split(':')))
dummy.col_cnt.value_counts()
4 1979
3 1200
5 88
Name: col_cnt, dtype: int64
Some sample tweets with different ‘:’’ counts
dummy[dummy.col_cnt == 3].head()
| created_at | id | screen_name | text | col_cnt | |
|---|---|---|---|---|---|
| 0 | 2017-11-16 23:52:20 | 931308990599979008 | 511centralva | Accident: SB on I-95 at MM75 in Richmond. Right shoulder closed.6:52PM | 3 |
| 2 | 2017-11-16 23:52:20 | 931308987340992517 | 511centralva | Disabled Vehicle: SB on I-95 at MM75 in Richmond. No lanes closed.6:52PM | 3 |
| 5 | 2017-11-16 23:40:17 | 931305957505847296 | 511centralva | Accident: NB on US-17 at MM112 in Essex Co. No lanes closed.6:40PM | 3 |
| 6 | 2017-11-16 23:36:23 | 931304974671368192 | 511centralva | Disabled Vehicle: WB on I-64 at MM218 in New Kent Co. 1 travel lane closed.6:36PM | 3 |
| 8 | 2017-11-16 23:22:24 | 931301456132562944 | 511centralva | Accident: NB on I-95 at MM78 in Richmond. Right shoulder closed.6:22PM | 3 |
dummy[dummy.col_cnt == 4].head()
| created_at | id | screen_name | text | col_cnt | |
|---|---|---|---|---|---|
| 1 | 2017-11-16 23:52:20 | 931308988968214528 | 511centralva | Update: Accident: SB on US-17 at MM112 in Essex Co. No lanes closed.6:52PM | 4 |
| 3 | 2017-11-16 23:52:19 | 931308985784946688 | 511centralva | Cleared: Accident: NB on US-17 at MM119 in Essex Co.6:52PM | 4 |
| 4 | 2017-11-16 23:50:26 | 931308511312666625 | 511centralva | Cleared: Disabled Vehicle: WB on I-64 at MM218 in New Kent Co.6:50PM | 4 |
| 7 | 2017-11-16 23:26:27 | 931302475562344448 | 511centralva | Cleared: Accident: WB on I-64 at MM187 in Richmond.6:24PM | 4 |
| 12 | 2017-11-16 23:06:31 | 931297456817606658 | 511centralva | Cleared: Accident: NB on I-95 at MM87 in Hanover Co.6:06PM | 4 |
dummy[dummy.col_cnt == 3]['text'].map(lambda x: x.split(':')[0]).value_counts()
Accident 714
Incident 237
Disabled Vehicle 111
bridge opening 57
utility work 18
Delay 17
Vehicle Fire 15
Disabled Tractor Trailer 13
brush fire 4
special event 3
maintenance 3
signal installation 2
bridge inspection 2
paving operations 1
bridge work 1
patching 1
road widening work 1
Name: text, dtype: int64
dummy[dummy.col_cnt == 4]['text'].map(lambda x: x.split(':')[0]).value_counts()
Cleared 1193
Update 727
Advisory 58
Closed 1
Name: text, dtype: int64
dummy[dummy.col_cnt == 5]['text'].map(lambda x: x.split(':')[0]).value_counts()
Cleared 59
Update 29
Name: text, dtype: int64
texts = dummy[dummy.text.str.contains('brush')]['text']
Form the Regex to parse tweet texts
import re
pattern = re.compile(r'((?P<status>\w+): )?'
r'(?P<advisory>(Advisory|Closed): )?'
r'(?P<type>(\w*\s?)+): '
r'(?P<direction>[NEWS]B )?on '
r'(?P<hwy>.*)( at)? '
r'((?P<loc>.*)) in '
r'(?P<city>[A-Za-z0-9 ]+).'
r'(?P<comment>[a-zA-Z0-9\.&;/ ]+.)?'
r'(?P<time>\d+:\d+[AP]M)$'
)
Test the regular expression to see if it works
attrs = ['status', 'type', 'direction', 'hwy', 'loc', 'city', 'comment', 'time']
for a in attrs:
t = 'Update: Accident: EB on I-64 at MM199 in Henrico Co. All travel lanes closed. Delay 1 mi.5:52PM'
t = 'Cleared: Accident: WB on I-64 at MM187 in Richmond.6:24PM'
print(f'{a} -> {pattern.match(t).group(a)}')
status -> Cleared
type -> Accident
direction -> WB
hwy -> I-64 at
loc -> MM187
city -> Richmond
comment -> None
time -> 6:24PM
Some texts throw the parser for a spin, so clean those handful of offensive tweets
dummy.iloc[1520]
dummy.drop(1520, inplace=True)
dummy.drop(1519, inplace=True)
dummy.iloc[1519]
created_at 2017-11-07 13:50:25
id 927896021925023750
screen_name 511centralva
text Accident: NB on I-195 at MM3 in Richmond. Right shoulder closed.8:50AM
status None
type Accident
direction NB
hwy I-195 at
loc MM3
city Richmond
comment Right shoulder closed.
time 8:50AM
Name: 1529, dtype: object
dummy.iloc[1518]
created_at 2017-11-07 13:50:26
id 927896023451783168
screen_name 511centralva
text maintenance: On Diascund Road North and South at Hockaday Road in New Kent Co. All NB & all SB travel lanes closed. Potential Delays.8:50AM
status NaN
type NaN
direction NaN
hwy NaN
loc NaN
city NaN
comment NaN
time NaN
Name: 1528, dtype: object
dummy.drop(1518, inplace=True)
dummy.drop(1527, inplace=True)
dummy.drop(1528, inplace=True)
dummy[dummy.text.str.contains('Diascund')]
| created_at | id | screen_name | text | status | type | direction | hwy | loc | city | comment | time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1146 | 2017-11-09 21:34:22 | 928737552491835392 | 511centralva | Cleared: maintenance: NB On Diascund Road North and South at Hockaday Road in New Kent Co.4:34PM | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Parse additional information from tweets text into data frame columns
Some tweets are still little wierd for regex parser, and we will skip those as well. But if we skip them, we will display them as well to keep track of the ones that were skipped.
for idx in dummy.index:
if idx%500 == 0:
print(idx)
try:
m = pattern.match(dummy.loc[idx,'text'])
for a in attrs:
dummy.loc[idx,a] = m.group(a)
except AttributeError:
print (dummy.loc[idx,'text'])
0
500
Cleared: Incident: NB (South Hopewell Street) in Hopewell.4:52PM
Incident: NB (South Hopewell Street) in Hopewell. No lanes closed.4:26PM
1000
Cleared: maintenance: NB On Diascund Road North and South at Hockaday Road in New Kent Co.4:34PM
1500
2000
2500
3000
3500
Update: bridge repair: EB On Scotts Road East and West between Canton Road and Level Green Road in Henrico Co. All EB & all WB travel10:32PM
bridge repair: On Scotts Road East and West between Canton Road and Level Green Road in Henrico Co. All EB & all WB travel lanes close9:52PM
4000
bridge work: at Gwynn's Island Bridge in Mathews Co. All NB & all SB travel lanes closed. Potential Delays.11:26AM
4500
Cleared: bridge repair: EB On Scotts Road East and West between Canton Road and Level Green Road in Henrico Co.9:58AM
Cleared: Incident: SB (Coleman Memorial Bridge) in Gloucester Co.8:08AM
Incident: SB (Coleman Memorial Bridge) in Gloucester Co. No lanes closed.7:30AM
5000
5500
6000
6500
import seaborn as sns
plt.style.use('fivethirtyeight')
Finally the output of parsing:
dummy.tail()
| created_at | id | screen_name | text | status | type | direction | hwy | loc | city | comment | time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6513 | 2017-09-21 06:36:24 | 910754565540151296 | 511centralva | Update: Incident: NB on I-95 at MM75 in Richmond. 1 SB travel lane closed.2:36AM | Update | Incident | NB | I-95 at | MM75 | Richmond | 1 SB travel lane closed. | 2:36AM |
| 6514 | 2017-09-21 06:24:24 | 910751549248466944 | 511centralva | Incident: NB on I-95 at MM75 in Richmond. No lanes closed.2:24AM | None | Incident | NB | I-95 at | MM75 | Richmond | No lanes closed. | 2:24AM |
| 6515 | 2017-09-21 05:44:25 | 910741486081384448 | 511centralva | Cleared: bridge opening: NB on VA-156 at B. Harrison Bridge in Prince George Co.1:44AM | Cleared | bridge opening | NB | VA-156 at B. Harrison | Bridge | Prince George Co | None | 1:44AM |
| 6516 | 2017-09-21 05:32:19 | 910738441587101697 | 511centralva | bridge opening: on VA-156 at B. Harrison Bridge in Prince George Co. All NB & all SB travel lanes closed. Potential Delays.1:32AM | None | bridge opening | None | VA-156 at B. Harrison | Bridge | Prince George Co | All NB & all SB travel lanes closed. Potential Delays. | 1:32AM |
| 6517 | 2017-09-21 03:10:25 | 910702730670374914 | 511centralva | Cleared: Incident: NB on I-95 at MM54 in Colonial Heights.11:10PM | Cleared | Incident | NB | I-95 at | MM54 | Colonial Heights | None | 11:10PM |
dummy.status.hasnans, dummy.type.hasnans
(True, False)
for idx in dummy[dummy.type.isnull()].index:
dummy.drop(idx, inplace=True)
reports = dummy[dummy.status.isnull()]
len(reports)
2348
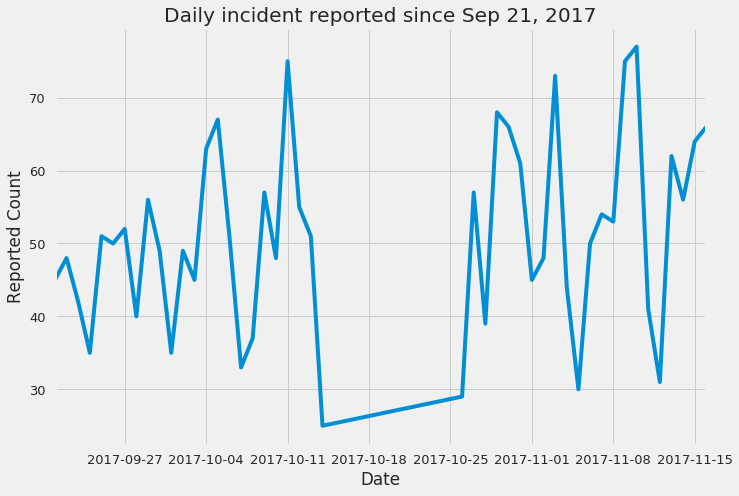
reports.created_at.dt.date.value_counts().plot()
plt.title('Daily incident reported since Sep 21, 2017')
plt.ylabel('Reported Count')
plt.xlabel('Date')
plt.show()
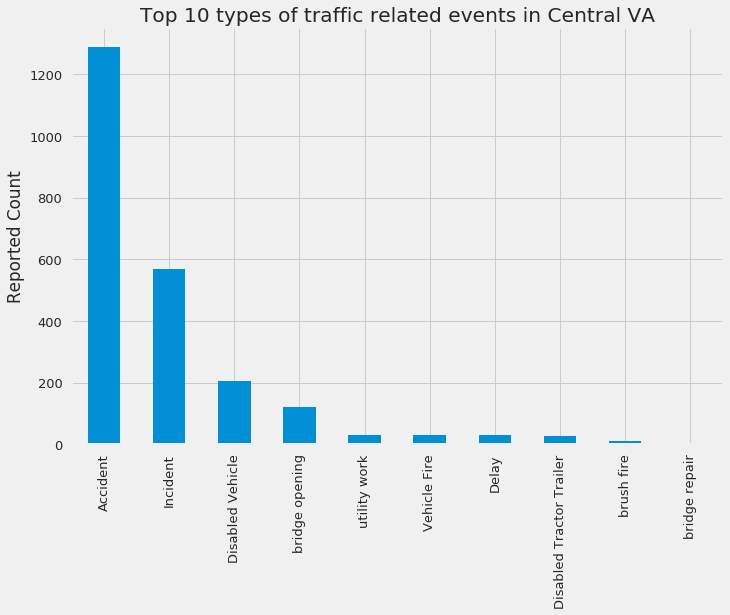
reports.type.value_counts(dropna=False)[:10].plot(kind='bar')
plt.ylabel('Reported Count')
plt.title('Top 10 types of traffic related events in Central VA')
plt.show()
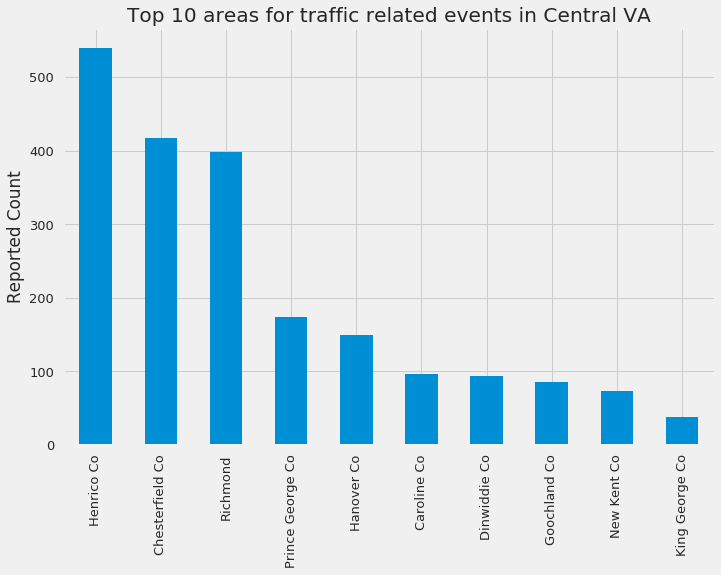
reports.city.value_counts(dropna=False)[:10].plot(kind='bar')
plt.ylabel('Reported Count')
plt.title('Top 10 areas for traffic related events in Central VA')
plt.show()
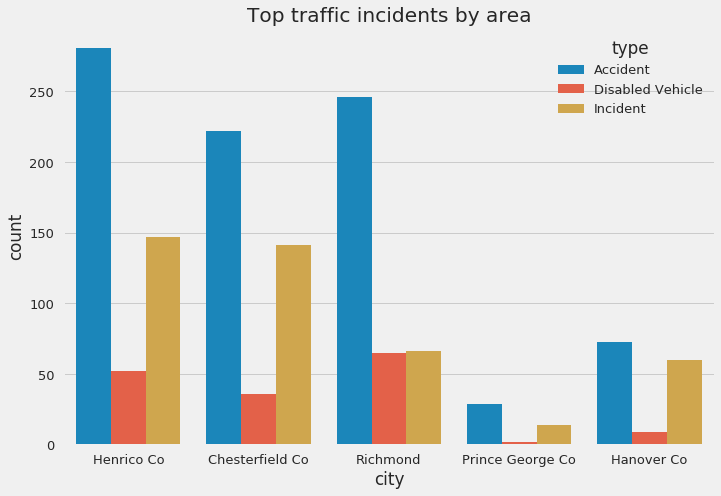
temp = reports.groupby(['type', 'city'])['id'].count().sort_values(ascending=False)[:20].to_frame()
temp.head()
| id | ||
|---|---|---|
| type | city | |
| Accident | Henrico Co | 281 |
| Richmond | 246 | |
| Chesterfield Co | 222 | |
| Incident | Henrico Co | 147 |
| Chesterfield Co | 141 |
def hitype(x):
return (x in ['Accident', 'Incident', 'Disabled Vehicle'])
sns.countplot(data=reports[reports.type.map(hitype)], x='city', hue='type', order=reports.city.value_counts().iloc[:5].index)
plt.title('Top traffic incidents by area')
plt.show()
Which county has the most accidents?
dummy.city.value_counts(dropna=False)[:10].plot(kind='bar')
plt.show()
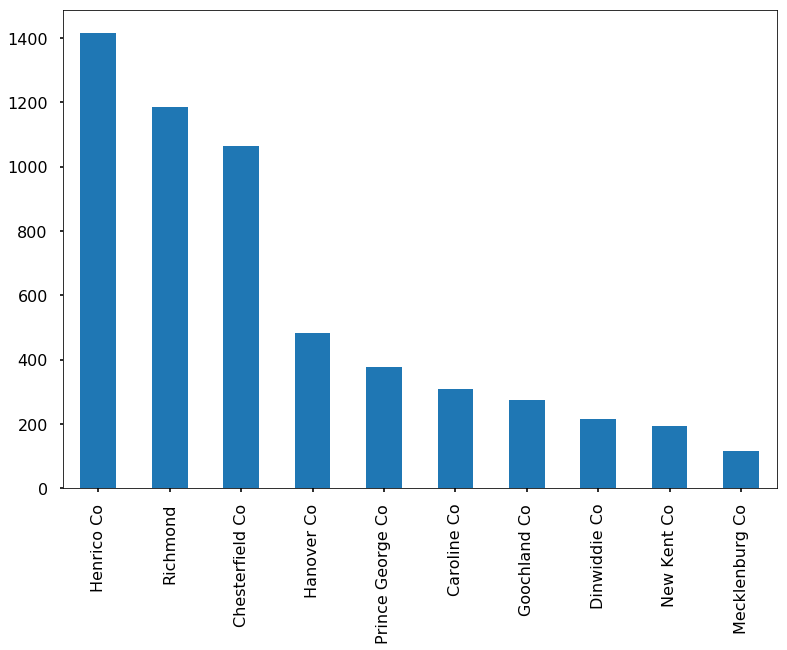
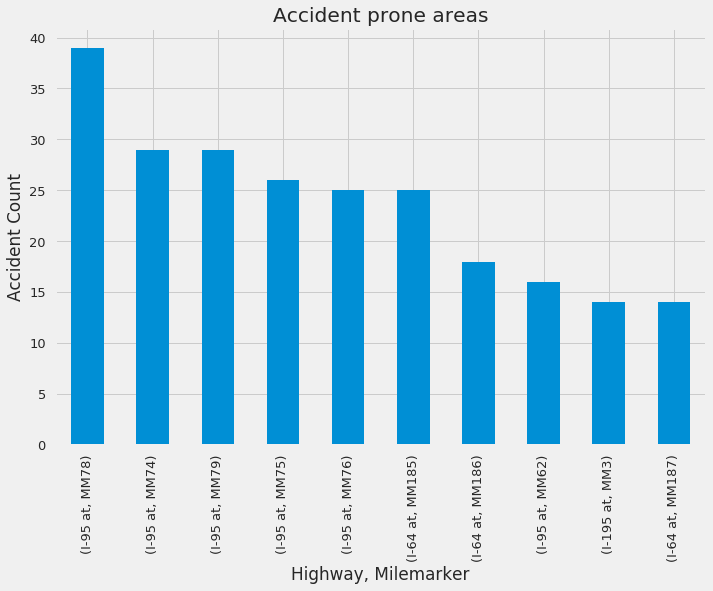
Where are the most accident prone zones?
Drive safe here!
reports[reports.type == 'Accident'].groupby(['hwy','loc'])['id'].count().sort_values(ascending=False)[:10].plot(kind='bar')
plt.title('Accident prone areas')
plt.xlabel('Highway, Milemarker')
plt.ylabel('Accident Count')
plt.show()
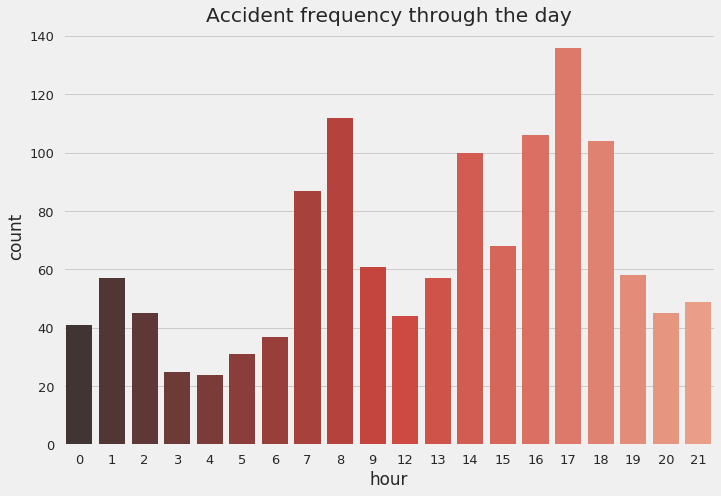
sns.countplot(data=reports[reports.type == 'Accident'], x='hour', palette='Reds_d')
plt.title('Accident frequency through the day')
plt.show()
Summary
Drive safe all the time! But especially around MM78 , MM74 and MM79 on I-95. Also apparently there 8am and 5pm are when most accidents happen. Do dont rush to office and relax when you drive back home. Unwind!