Hyperparameter Tuning & ML Pipelines
This is the notebook underlying the reveal.js slides that were used for Richmond Data Science community meetup on May 30th, 2018.
About me:
I am Atul Saurav (@twtAtul),
- Lead Genworth Financials’ Data Engineering Team
- MS in Decison Analytics, VCU DAPT class of 2019
- Passionate about learning, data and everything around it
You can also find me on LinkedIn
What is this talk about?
- Building Machine Learning Models
- Python specific
- scikit-learn based models
What is this talk not about?
- Data Cleansing
- Feature Engineering
- Deep Learning
- Other exciting stuff that is difficult to cover in 1 meetup!
All models are wrong but some are useful
</br> </br>
Box, G. E. P. (1979), "Robustness in the strategy of scientific model building", in Launer, R. L.; Wilkinson, G. N., Robustness in Statistics, Academic Press, pp. 201–236.
Reality is complex -
too many factors influence outcome
factors difficult to measure accurately and objectively
not all factors may be known
How do we build useful models?
How do we minimize our effort in model building?
Approach
- Use toy datasets for illustration and visualization
- Use real dataset for demonstrating application efficacy
Scikit-learn API Overview
- All methods are implemented as estimators
- All estimators have a
.fit()method - All supervised estimators have
.predict()method - All unsupervised estimators have
.transform()method
| ``model.predict`` | ``model.transform`` |
|---|---|
| Classification | Preprocessing |
| Regression | Dimensionality Reduction |
| Clustering | Feature Extraction |
| Feature Selection |
Usual High Level Flow
from sklearn.family import SomeModel
myModel = SomeModel()
myModel.fit(X_train,y_train)
# supervised
myModel.predict(X_test)
myModel.score(X_test, y_test)
## unsupervised
myModel.transform(X_train)
Problem Statement
- Classify data into 2 groups based on already observed groupings
- Using house price data, predict if the price of the given house will be >= 500K
Binary Classification Problem
Toy Example
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
plt.style.use('seaborn-poster')
_ = plt.xkcd()
from sklearn.datasets import make_blobs
scaled_X, scaled_y = make_blobs(centers=2, random_state=0)
scaled_X[:,0] = 10* scaled_X[:,0] + 3
X, y = make_blobs(centers=2, random_state=0)
print('X ~ n_samples x n_features:', X.shape)
print('y ~ n_samples:', y.shape)
X ~ n_samples x n_features: (100, 2)
y ~ n_samples: (100,)
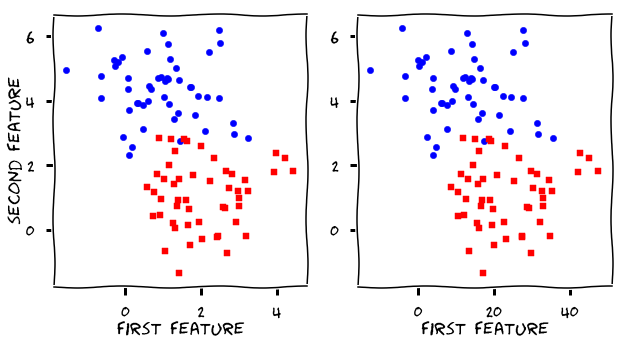
Visualize Data
fig, (ax0, ax1) = plt.subplots(nrows=1, ncols=2, figsize=(10,5))
ax0.scatter(X[y == 0, 0], X[y == 0, 1], c='blue', s=40, label='0')
ax0.scatter(X[y == 1, 0], X[y == 1, 1], c='red', s=40, label='1', marker='s')
ax0.set_xlabel('first feature')
ax0.set_ylabel('second feature')
ax1.scatter(scaled_X[scaled_y == 0, 0], scaled_X[scaled_y == 0, 1], c='blue', s=40, label='0')
ax1.scatter(scaled_X[scaled_y == 1, 0], scaled_X[scaled_y == 1, 1], c='red', s=40, label='1', marker='s')
ax1.set_xlabel('first feature')
Text(0.5,0,'first feature')
Create Training and Test Set
Training Set - Data used to train the model
Test Set - Data held out in the very beginning for testing model performance. This data should not be touched until final scoring
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25,
random_state=1234,
stratify=y)
scaled_X_train, scaled_X_test, \
scaled_y_train, scaled_y_test = train_test_split(scaled_X,
scaled_y,
test_size=0.25,
random_state=1234,
stratify=y)
X_train.shape
(75, 2)
y_train.shape
(75,)
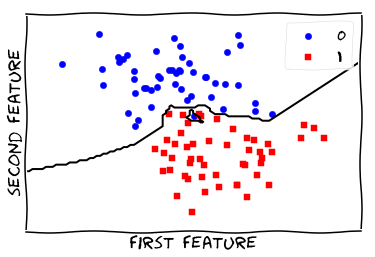
Train a Nearest Neighbor Classifier - 1 Neighbor
Overfit!!
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
scaled_knn = KNeighborsClassifier(n_neighbors=1)
scaled_knn.fit(scaled_X_train, scaled_y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Comapre Model Performance
knn.score(X_test, y_test)
1.0
scaled_knn.score(scaled_X_test, scaled_y_test)
0.95999999999999996
Visualize Model - regular
from figures import plot_2d_separator
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='blue', s=40, label='0')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(knn, X)
_ = plt.legend()
Visualize Model - scaled
from figures import plot_2d_separator
plt.scatter(scaled_X[scaled_y == 0, 0], scaled_X[scaled_y == 0, 1], c='blue', s=40, label='0')
plt.scatter(scaled_X[scaled_y == 1, 0], scaled_X[scaled_y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(scaled_knn, scaled_X)
_ = plt.legend()
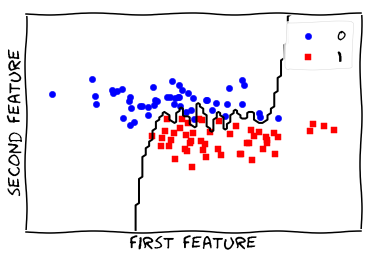
Revelation
Scale of various features matters!
Train Nearest Neighbor Classifier - 10 neighbors
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=10, p=2,
weights='uniform')
scaled_knn = KNeighborsClassifier(n_neighbors=10)
scaled_knn.fit(scaled_X_train, scaled_y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=10, p=2,
weights='uniform')
Comapre Model Performance
knn.score(X_test, y_test)
0.83999999999999997
scaled_knn.score(scaled_X_test, scaled_y_test)
0.80000000000000004
Visualize Model - regular
from figures import plot_2d_separator
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='blue', s=40, label='0')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(knn, X)
_ = plt.legend()
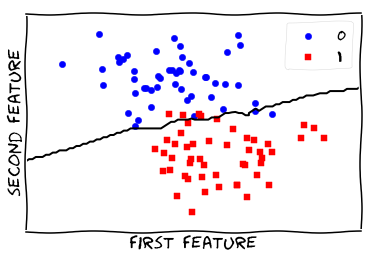
Visualize Model - scaled
from figures import plot_2d_separator
plt.scatter(scaled_X[scaled_y == 0, 0], scaled_X[scaled_y == 0, 1], c='blue', s=40, label='0')
plt.scatter(scaled_X[scaled_y == 1, 0], scaled_X[scaled_y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(scaled_knn, scaled_X)
_ = plt.legend()
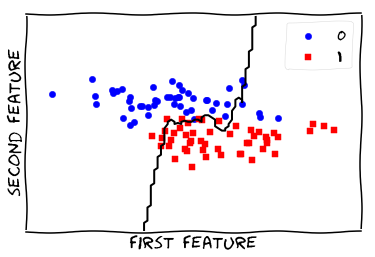
Revelation
Number of neighbors matters as well!
Tunning # of Neighbors
train_scores = []
test_scores = []
n_neighbors = range(1,28)
for neighbor in n_neighbors:
knn = KNeighborsClassifier(n_neighbors=neighbor)
knn.fit(X_train, y_train)
train_scores.append(knn.score(X_train, y_train))
test_scores.append(knn.score(X_test, y_test))
plt.plot(n_neighbors, train_scores, label='train')
plt.plot(n_neighbors, test_scores, label='test')
plt.ylabel('Accuracy')
plt.xlabel('# of neighbors')
plt.legend();plt.show()
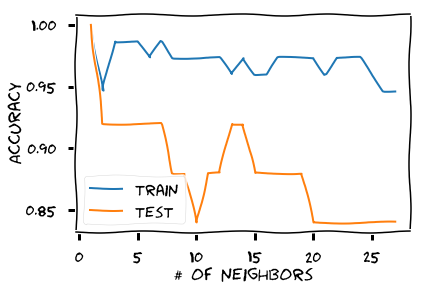
But Wait!! Is that Hyperparameter Tuning?
No
Hyperparameter tuning is part of Model building and Test Data should not be used in model build
Hyperparameter Tuning should be performed using Validation Set - a subset of training set
import pandas as pd
# get columns with null - to return sorted in future
def null_pct(df):
return { k:sum(df[k].isnull())/len(df) for k in df.columns}
def null_count(df):
return { k:sum(df[k].isnull()) for k in df.columns}
from sklearn.base import TransformerMixin, BaseEstimator
class CategoricalTransformer(BaseEstimator, TransformerMixin):
"Converts a set of columns in a DataFrame to categoricals"
def __init__(self, columns):
self.columns = columns
def fit(self, X, y=None):
'Records the categorical information'
self.cat_map_ = {col: X[col].astype('category').cat
for col in self.columns}
return self
def transform(self, X, y=None):
X = X.copy()
for col in self.columns:
X[col] = pd.Categorical(X[col],
categories=self.cat_map_[col].categories,
ordered=self.cat_map_[col].ordered)
return X
def inverse_transform(self, trn, y=None):
trn = trn.copy()
trn[self.columns] = trn[self.columns].apply(lambda x: x.astype(object))
return trn
class DummyEncoder(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
self.columns_ = X.columns
self.cat_cols_ = X.select_dtypes(include=['category']).columns
self.non_cat_cols_ = X.columns.drop(self.cat_cols_)
self.cat_map_ = {col: X[col].cat for col in self.cat_cols_}
self.cat_blocks_ = {} # {cat col: slice}
left = len(self.non_cat_cols_)
for col in self.cat_cols_:
right = left + len(self.cat_map_[col].categories)
self.cat_blocks_[col] = slice(left, right)
left = right
return self
def transform(self, X, y=None):
return np.asarray(pd.get_dummies(X))
def inverse_transform(self, trn, y=None):
numeric = pd.DataFrame(trn[:, :len(self.non_cat_cols_)],
columns=self.non_cat_cols_)
series = []
for col, slice_ in self.cat_blocks_.items():
codes = trn[:, slice_].argmax(1)
cat = self.cat_map_[col]
cat = pd.Categorical.from_codes(codes,
cat.categories,
cat.ordered)
series.append(pd.Series(cat, name=col))
return pd.concat([numeric] + series, axis='columns')[self.columns_]
Real Life Example - Housing Data
data = pd.read_csv('new_train.csv')
data.columns = [ x.lower().replace('.','_') for x in data.columns]
data.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| id | 1 | 2 | 3 | 4 | 5 |
| sale_type | MLS Listing | MLS Listing | MLS Listing | MLS Listing | MLS Listing |
| sold_date | NaN | NaN | NaN | NaN | NaN |
| property_type | Condo/Co-op | Single Family Residential | Single Family Residential | Single Family Residential | Single Family Residential |
| city | Kew Gardens | Anaheim | Howard Beach | Aliso Viejo | Orlando |
| state | NY | CA | NY | CA | FL |
| zip | 11415 | 92807 | 11414 | 92656 | 32837 |
| beds | 0 | 7 | 3 | 4 | 3 |
| baths | 1 | 5.5 | 1.5 | 4.5 | 2 |
| location | The Texas | 91 - Sycamore Canyon | Howard Beach | AV - Aliso Viejo | Orlando |
| square_feet | NaN | 7400 | NaN | 3258 | 1596 |
| lot_size | NaN | 56628 | 2400 | 5893 | 5623 |
| year_built | 1956 | 2000 | 1950 | 2011 | 1994 |
| days_on_market | 1 | 2 | 15 | 6 | 8 |
| x__square_feet | NaN | 514 | NaN | 457 | 166 |
| hoa_month | NaN | NaN | NaN | 258 | 64 |
| status | Active | Active | Active | Active | Active |
| next_open_house_start_time | March-11-2018 01:00 PM | NaN | NaN | NaN | NaN |
| next_open_house_end_time | March-11-2018 03:00 PM | NaN | NaN | NaN | NaN |
| source | MLSLI | CRMLS | MLSLI | CRMLS | MFRMLS |
| favorite | N | N | N | N | N |
| interested | Y | Y | Y | Y | Y |
| latitude | 40.7 | 33.8 | 40.7 | 33.6 | 28.4 |
| longitude | -73.8 | -117.8 | -73.8 | -117.7 | -81.4 |
| target | False | True | True | True | False |
Some Observations
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 19318 entries, 0 to 19317
Data columns (total 25 columns):
id 19318 non-null int64
sale_type 19318 non-null object
sold_date 0 non-null float64
property_type 19318 non-null object
city 19306 non-null object
state 19318 non-null object
zip 19271 non-null object
beds 18216 non-null float64
baths 18053 non-null float64
location 18773 non-null object
square_feet 15693 non-null float64
lot_size 10267 non-null float64
year_built 16950 non-null float64
days_on_market 18328 non-null float64
x__square_feet 15693 non-null float64
hoa_month 7553 non-null float64
status 19318 non-null object
next_open_house_start_time 933 non-null object
next_open_house_end_time 933 non-null object
source 19318 non-null object
favorite 19318 non-null object
interested 19318 non-null object
latitude 19318 non-null float64
longitude 19318 non-null float64
target 19318 non-null bool
dtypes: bool(1), float64(11), int64(1), object(12)
memory usage: 3.6+ MB
What’s different?
- Not all features are numeric - **Categorical Variables **
- Lot of missing data points
More Revalations:
scikit-learn models need data to be numeric/float
scikit-learn models implicitly cannot handle missing values
Final Revelation
Any transformation applied on the training set to handle first 3 revelations should later be applied on the test set as well
del(data['sold_date'])
del(data['next_open_house_start_time'])
del(data['next_open_house_end_time'])
Summary so far
We need to string following steps into a managable fashion to build effective models
- Handle missing data
- Handle different scales across features
- Handle categorical data
- Pipelines
But then also tune the model
- split training data into (cross)validation sets
- search best values for hyperparameters for optimal model performance
- GridSearch
More on Pipelines and GridSearchCV
- also known as meta-estimators in scikit-learn
- they inherit the properties of the last estimator used
- pipeline is used to chain multiple estimator into one pipe so output of one flows as input of next
- GridSearchCV is used to search on a hyperparameter grid the model with the best score
Making ML Pipelines
from sklearn.pipeline import make_pipeline
make_pipeline( CategoricalTransformer(columns=cat_cols), DummyClassifier("most_frequent"))
This will inherit the properties of DummyClassifier

Image Source: SciPy 2016 Scikit-learn Tutorial
Back to real life housing classification problem
Which features have less than 20% missing values?
d = pd.DataFrame(null_pct(data), index=['null_pct']).T.sort_values('null_pct')
d[(d.null_pct< .2 )]
| null_pct | |
|---|---|
| id | 0.000000 |
| latitude | 0.000000 |
| interested | 0.000000 |
| favorite | 0.000000 |
| source | 0.000000 |
| status | 0.000000 |
| longitude | 0.000000 |
| target | 0.000000 |
| state | 0.000000 |
| property_type | 0.000000 |
| sale_type | 0.000000 |
| city | 0.000621 |
| zip | 0.002433 |
| location | 0.028212 |
| days_on_market | 0.051248 |
| beds | 0.057045 |
| baths | 0.065483 |
| year_built | 0.122580 |
| square_feet | 0.187649 |
| x__square_feet | 0.187649 |
Set features to work with
new_features = ['id', 'favorite', 'interested', 'latitude', 'longitude', 'status', 'property_type', 'sale_type', 'source',
'state', 'beds', 'baths', 'year_built', 'x__square_feet', 'square_feet', 'target']
sub_data = data[new_features]
sub_data.head(3)
| id | favorite | interested | latitude | longitude | status | property_type | sale_type | source | state | beds | baths | year_built | x__square_feet | square_feet | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | N | Y | 40.7 | -73.8 | Active | Condo/Co-op | MLS Listing | MLSLI | NY | 0.0 | 1.0 | 1956.0 | NaN | NaN | False |
| 1 | 2 | N | Y | 33.8 | -117.8 | Active | Single Family Residential | MLS Listing | CRMLS | CA | 7.0 | 5.5 | 2000.0 | 514.0 | 7400.0 | True |
| 2 | 3 | N | Y | 40.7 | -73.8 | Active | Single Family Residential | MLS Listing | MLSLI | NY | 3.0 | 1.5 | 1950.0 | NaN | NaN | True |
print (len(sub_data))
sub_data = sub_data.drop_duplicates(subset=['favorite', 'interested', 'latitude', 'longitude', 'status', 'property_type', 'sale_type',
'source', 'state', 'beds', 'baths', 'year_built', 'x__square_feet', 'square_feet', 'target'])
print (len(sub_data))
19318
17815
sub_data = sub_data.copy()
sub_data.loc[sub_data['sale_type'] == 'New Construction Plan','year_built'] = 2018.0
sub_data.loc[sub_data['property_type'] == 'Vacant Land','year_built'] = 2019.0
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score, roc_curve, make_scorer
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegressionCV
from sklearn.svm import SVC, LinearSVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import Imputer, RobustScaler, StandardScaler
def plot_roc(model, X_test, y_test):
df = model.decision_function(X_test)
fpr, tpr, _ = roc_curve(y_test, df)
acc = model.score(X_test, y_test)
auc0 = roc_auc_score(y_test, df)
auc1 = roc_auc_score(y_test, model.predict(X_test))
plt.plot(fpr, tpr, label="acc:%.2f auc0:%.2f auc1:%.2f" % (acc, auc0, auc1), linewidth=3)
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate (recall)")
plt.title(repr(model).split('(')[0])
plt.legend(loc="best");
roc_auc_scorer = make_scorer(roc_auc_score, greater_is_better=True,
needs_threshold=True)
Set model Inputs
X = sub_data[['favorite', 'interested', 'latitude', 'longitude', 'status', 'property_type', 'sale_type',
'source', 'state', 'beds', 'baths', 'year_built', 'x__square_feet', 'square_feet']]
y = sub_data.target
cat_cols = ['favorite', 'interested', 'status', 'property_type', 'sale_type', 'source', 'state']
Establish base case for prediction
dummy_pipe = make_pipeline( CategoricalTransformer(columns=cat_cols), DummyEncoder(), DummyClassifier("most_frequent"))
cross_val_score(dummy_pipe, X, y)
array([ 0.68984678, 0.68996295, 0.68996295])
Create training and test set
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state=42 )
Support Vector Machine
Cs = [ 1, 10, 100, 500, 750]
gammas = [0.0005, 0.001, 0.01, .1, 1]
param_grid = {'svc__C': Cs, 'svc__gamma' : gammas}
svc_pipe = make_pipeline( CategoricalTransformer(columns=cat_cols), DummyEncoder(), Imputer(strategy='median'), StandardScaler(), SVC(random_state=42) )
svmgrid = GridSearchCV(svc_pipe, param_grid, cv=5, n_jobs=-1, verbose=3)#, scoring=roc_auc_scorer)
svmgrid.fit(X_train, y_train)
Fitting 5 folds for each of 25 candidates, totalling 125 fits
[CV] svc__C=1, svc__gamma=0.0005 .....................................
[CV] svc__C=1, svc__gamma=0.0005 .....................................
[CV] svc__C=1, svc__gamma=0.0005 .....................................
[CV] svc__C=1, svc__gamma=0.0005 .....................................
[CV] svc__C=1, svc__gamma=0.0005 .....................................
[CV] svc__C=1, svc__gamma=0.001 ......................................
[CV] svc__C=1, svc__gamma=0.001 ......................................
[CV] svc__C=1, svc__gamma=0.001 ......................................
[CV] svc__C=1, svc__gamma=0.001, score=0.8323980546202768, total= 17.9s
[CV] svc__C=1, svc__gamma=0.001 ......................................
[CV] svc__C=1, svc__gamma=0.0005, score=0.7875046763935653, total= 19.0s
[CV] svc__C=1, svc__gamma=0.001 ......................................
[CV] svc__C=1, svc__gamma=0.001, score=0.7639356528245417, total= 19.4s
[CV] svc__C=1, svc__gamma=0.01 .......................................
[CV] svc__C=1, svc__gamma=0.001, score=0.780314371257485, total= 19.2s
[CV] svc__C=1, svc__gamma=0.01 .......................................
[CV] svc__C=1, svc__gamma=0.0005, score=0.7542087542087542, total= 19.8s
[CV] svc__C=1, svc__gamma=0.01 .......................................
[CV] svc__C=1, svc__gamma=0.0005, score=0.7746162485960314, total= 20.2s
[CV] svc__C=1, svc__gamma=0.01 .......................................
[CV] svc__C=1, svc__gamma=0.0005, score=0.7690868263473054, total= 20.4s
[CV] svc__C=1, svc__gamma=0.01 .......................................
[CV] svc__C=1, svc__gamma=0.0005, score=0.7784431137724551, total= 20.6s
[CV] svc__C=1, svc__gamma=0.1 ........................................
[CV] svc__C=1, svc__gamma=0.01, score=0.8787878787878788, total= 13.7s
[CV] svc__C=1, svc__gamma=0.1 ........................................
[CV] svc__C=1, svc__gamma=0.1, score=0.8327721661054994, total= 14.7s
[CV] svc__C=1, svc__gamma=0.1 ........................................
[CV] svc__C=1, svc__gamma=0.01, score=0.8166853722409277, total= 16.5s
[CV] svc__C=1, svc__gamma=0.1 ........................................
[CV] svc__C=1, svc__gamma=0.01, score=0.844311377245509, total= 16.5s
[CV] svc__C=1, svc__gamma=0.1 ........................................
[CV] svc__C=1, svc__gamma=0.01, score=0.8352676900037439, total= 16.2s
[CV] svc__C=1, svc__gamma=0.01, score=0.8334580838323353, total= 16.7s
[CV] svc__C=1, svc__gamma=1 ..........................................
[CV] svc__C=1, svc__gamma=1 ..........................................
[CV] svc__C=1, svc__gamma=0.001, score=0.7907934131736527, total= 18.7s
[CV] svc__C=1, svc__gamma=1 ..........................................
[CV] svc__C=1, svc__gamma=0.001, score=0.7858479970048671, total= 18.5s
[CV] svc__C=1, svc__gamma=1 ..........................................
[Parallel(n_jobs=-1)]: Done 16 tasks | elapsed: 55.7s
[CV] svc__C=1, svc__gamma=0.1, score=0.8843995510662177, total= 14.3s
[CV] svc__C=1, svc__gamma=1 ..........................................
[CV] . svc__C=1, svc__gamma=1, score=0.9042274597830153, total= 14.2s
[CV] svc__C=10, svc__gamma=0.0005 ....................................
[CV] svc__C=1, svc__gamma=0.1, score=0.8510479041916168, total= 15.9s
[CV] svc__C=10, svc__gamma=0.0005 ....................................
[CV] svc__C=1, svc__gamma=0.1, score=0.847997004867091, total= 15.5s
[CV] svc__C=10, svc__gamma=0.0005 ....................................
[CV] svc__C=1, svc__gamma=0.1, score=0.8401946107784432, total= 16.3s
[CV] svc__C=10, svc__gamma=0.0005 ....................................
[CV] . svc__C=1, svc__gamma=1, score=0.8514777403666293, total= 16.0s
[CV] svc__C=10, svc__gamma=0.0005 ....................................
[CV] . svc__C=1, svc__gamma=1, score=0.8589071856287425, total= 16.2s
[CV] svc__C=10, svc__gamma=0.001 .....................................
[CV] . svc__C=1, svc__gamma=1, score=0.8581586826347305, total= 15.8s
[CV] svc__C=10, svc__gamma=0.001 .....................................
[CV] . svc__C=1, svc__gamma=1, score=0.8629726694122052, total= 15.0s
[CV] svc__C=10, svc__gamma=0.001 .....................................
[CV] svc__C=10, svc__gamma=0.0005, score=0.8769173213617658, total= 15.3s
[CV] svc__C=10, svc__gamma=0.001 .....................................
[CV] svc__C=10, svc__gamma=0.001, score=0.8903853348297793, total= 14.2s
[CV] svc__C=10, svc__gamma=0.001 .....................................
[CV] svc__C=10, svc__gamma=0.0005, score=0.7942386831275721, total= 17.5s
[CV] svc__C=10, svc__gamma=0.01 ......................................
[CV] svc__C=10, svc__gamma=0.0005, score=0.8244760479041916, total= 17.8s
[CV] svc__C=10, svc__gamma=0.01 ......................................
[CV] svc__C=10, svc__gamma=0.001, score=0.8065843621399177, total= 17.4s
[CV] svc__C=10, svc__gamma=0.0005, score=0.8181137724550899, total= 18.3s
[CV] svc__C=10, svc__gamma=0.01 ......................................
[CV] svc__C=10, svc__gamma=0.01 ......................................
[CV] svc__C=10, svc__gamma=0.0005, score=0.8172968925496069, total= 18.2s
[CV] svc__C=10, svc__gamma=0.01 ......................................
[CV] svc__C=10, svc__gamma=0.001, score=0.8327095808383234, total= 16.5s
[CV] svc__C=10, svc__gamma=0.1 .......................................
[CV] svc__C=10, svc__gamma=0.01, score=0.9176954732510288, total= 11.6s
[CV] svc__C=10, svc__gamma=0.1 .......................................
[CV] svc__C=10, svc__gamma=0.01, score=0.8555929667040778, total= 14.0s
[CV] svc__C=10, svc__gamma=0.1 .......................................
[CV] svc__C=10, svc__gamma=0.001, score=0.8308383233532934, total= 17.0s
[CV] svc__C=10, svc__gamma=0.1 .......................................
[CV] svc__C=10, svc__gamma=0.01, score=0.8768712574850299, total= 14.2s
[CV] svc__C=10, svc__gamma=0.1 .......................................
[CV] svc__C=10, svc__gamma=0.01, score=0.8573567952077873, total= 14.2s
[CV] svc__C=10, svc__gamma=0.01, score=0.8566616766467066, total= 14.6s
[CV] svc__C=10, svc__gamma=1 .........................................
[CV] svc__C=10, svc__gamma=1 .........................................
[CV] svc__C=10, svc__gamma=0.001, score=0.8296518157993261, total= 16.9s
[CV] svc__C=10, svc__gamma=1 .........................................
[CV] svc__C=10, svc__gamma=0.1, score=0.9259259259259259, total= 10.5s
[CV] svc__C=10, svc__gamma=1 .........................................
[CV] svc__C=10, svc__gamma=0.1, score=0.8600823045267489, total= 13.9s
[CV] svc__C=10, svc__gamma=1 .........................................
[CV] svc__C=10, svc__gamma=0.1, score=0.8697604790419161, total= 13.9s
[CV] svc__C=100, svc__gamma=0.0005 ...................................
[CV] svc__C=10, svc__gamma=1, score=0.9266741488963711, total= 12.2s
[CV] svc__C=100, svc__gamma=0.0005 ...................................
[CV] svc__C=10, svc__gamma=0.1, score=0.8645209580838323, total= 13.8s
[CV] svc__C=100, svc__gamma=0.0005 ...................................
[CV] svc__C=10, svc__gamma=0.1, score=0.871209284912018, total= 14.1s
[CV] svc__C=100, svc__gamma=0.0005 ...................................
[CV] svc__C=10, svc__gamma=1, score=0.8873502994011976, total= 14.0s
[CV] svc__C=100, svc__gamma=0.0005 ...................................
[CV] svc__C=10, svc__gamma=1, score=0.8829031051253273, total= 14.9s
[CV] svc__C=100, svc__gamma=0.001 ....................................
[CV] svc__C=10, svc__gamma=1, score=0.8828592814371258, total= 13.3s
[CV] svc__C=100, svc__gamma=0.001 ....................................
[CV] svc__C=10, svc__gamma=1, score=0.8888056907525271, total= 12.8s
[CV] svc__C=100, svc__gamma=0.001 ....................................
[CV] svc__C=100, svc__gamma=0.0005, score=0.9075944631500187, total= 12.9s
[CV] svc__C=100, svc__gamma=0.001 ....................................
[CV] svc__C=100, svc__gamma=0.0005, score=0.8338945005611672, total= 16.1s
[CV] svc__C=100, svc__gamma=0.001 ....................................
[CV] svc__C=100, svc__gamma=0.0005, score=0.843937125748503, total= 16.0s
[CV] svc__C=100, svc__gamma=0.01 .....................................
[CV] svc__C=100, svc__gamma=0.001, score=0.8537224092779648, total= 15.2s
[CV] svc__C=100, svc__gamma=0.01 .....................................
[CV] svc__C=100, svc__gamma=0.0005, score=0.8476796407185628, total= 16.6s
[CV] svc__C=100, svc__gamma=0.01 .....................................
[CV] svc__C=100, svc__gamma=0.0005, score=0.8457506551853239, total= 16.6s
[CV] svc__C=100, svc__gamma=0.01 .....................................
[CV] svc__C=100, svc__gamma=0.001, score=0.9173213617658063, total= 11.4s
[CV] svc__C=100, svc__gamma=0.01 .....................................
[CV] svc__C=100, svc__gamma=0.001, score=0.8648952095808383, total= 14.5s
[CV] svc__C=100, svc__gamma=0.1 ......................................
[CV] svc__C=100, svc__gamma=0.01, score=0.9334081556303778, total= 8.7s
[CV] svc__C=100, svc__gamma=0.1 ......................................
[CV] svc__C=100, svc__gamma=0.001, score=0.8615269461077845, total= 14.9s
[CV] svc__C=100, svc__gamma=0.1 ......................................
[CV] svc__C=100, svc__gamma=0.01, score=0.8806584362139918, total= 12.3s
[CV] svc__C=100, svc__gamma=0.1 ......................................
[CV] svc__C=100, svc__gamma=0.001, score=0.8539872706851367, total= 14.5s
[CV] svc__C=100, svc__gamma=0.1 ......................................
[CV] svc__C=100, svc__gamma=0.01, score=0.8948353293413174, total= 12.0s
[CV] svc__C=100, svc__gamma=1 ........................................
[CV] svc__C=100, svc__gamma=0.01, score=0.8854790419161677, total= 12.3s
[CV] svc__C=100, svc__gamma=1 ........................................
[CV] svc__C=100, svc__gamma=0.01, score=0.8831898165481094, total= 12.0s
[CV] svc__C=100, svc__gamma=1 ........................................
[CV] svc__C=100, svc__gamma=0.1, score=0.9375233819678264, total= 7.8s
[CV] svc__C=100, svc__gamma=1 ........................................
[CV] svc__C=100, svc__gamma=0.1, score=0.8881406659184437, total= 11.6s
[CV] svc__C=100, svc__gamma=1 ........................................
[CV] svc__C=100, svc__gamma=0.1, score=0.9004491017964071, total= 11.9s
[CV] svc__C=500, svc__gamma=0.0005 ...................................
[CV] svc__C=100, svc__gamma=1, score=0.9438832772166106, total= 9.7s
[CV] svc__C=500, svc__gamma=0.0005 ...................................
[CV] svc__C=100, svc__gamma=0.1, score=0.8948353293413174, total= 12.2s
[CV] svc__C=500, svc__gamma=0.0005 ...................................
[CV] svc__C=100, svc__gamma=0.1, score=0.8955447397978286, total= 11.6s
[CV] svc__C=500, svc__gamma=0.0005 ...................................
[CV] svc__C=100, svc__gamma=1, score=0.9023569023569024, total= 12.9s
[CV] svc__C=500, svc__gamma=0.0005 ...................................
[CV] svc__C=100, svc__gamma=1, score=0.906062874251497, total= 13.3s
[CV] svc__C=500, svc__gamma=0.001 ....................................
[CV] svc__C=100, svc__gamma=1, score=0.905314371257485, total= 13.2s
[CV] svc__C=500, svc__gamma=0.001 ....................................
[CV] svc__C=100, svc__gamma=1, score=0.8989142643204793, total= 12.7s
[CV] svc__C=500, svc__gamma=0.001 ....................................
[CV] svc__C=500, svc__gamma=0.0005, score=0.9225589225589226, total= 10.4s
[CV] svc__C=500, svc__gamma=0.001 ....................................
[CV] svc__C=500, svc__gamma=0.0005, score=0.8649457538346427, total= 14.5s
[CV] svc__C=500, svc__gamma=0.001 ....................................
[CV] svc__C=500, svc__gamma=0.0005, score=0.874625748502994, total= 14.1s
[CV] svc__C=500, svc__gamma=0.01 .....................................
[CV] svc__C=500, svc__gamma=0.0005, score=0.8708832335329342, total= 14.2s
[CV] svc__C=500, svc__gamma=0.01 .....................................
[CV] svc__C=500, svc__gamma=0.001, score=0.9270482603815937, total= 10.5s
[CV] svc__C=500, svc__gamma=0.01 .....................................
[CV] svc__C=500, svc__gamma=0.001, score=0.8750467639356528, total= 13.5s
[CV] svc__C=500, svc__gamma=0.01 .....................................
[CV] svc__C=500, svc__gamma=0.0005, score=0.8655934107076001, total= 15.3s
[CV] svc__C=500, svc__gamma=0.01 .....................................
[CV] svc__C=500, svc__gamma=0.001, score=0.8866017964071856, total= 13.3s
[CV] svc__C=500, svc__gamma=0.1 ......................................
[CV] svc__C=500, svc__gamma=0.01, score=0.9393939393939394, total= 7.3s
[CV] svc__C=500, svc__gamma=0.1 ......................................
[CV] svc__C=500, svc__gamma=0.001, score=0.8806137724550899, total= 13.2s
[CV] svc__C=500, svc__gamma=0.1 ......................................
[CV] svc__C=500, svc__gamma=0.01, score=0.9019827908716798, total= 11.3s
[CV] svc__C=500, svc__gamma=0.1 ......................................
[CV] svc__C=500, svc__gamma=0.001, score=0.8745788094346687, total= 13.1s
[CV] svc__C=500, svc__gamma=0.1 ......................................
[CV] svc__C=500, svc__gamma=0.01, score=0.9191616766467066, total= 11.5s
[CV] svc__C=500, svc__gamma=1 ........................................
[CV] svc__C=500, svc__gamma=0.01, score=0.9109281437125748, total= 11.8s
[CV] svc__C=500, svc__gamma=1 ........................................
[CV] svc__C=500, svc__gamma=0.01, score=0.9041557469112692, total= 11.6s
[CV] svc__C=500, svc__gamma=1 ........................................
[CV] svc__C=500, svc__gamma=0.1, score=0.9476243920688365, total= 8.5s
[CV] svc__C=500, svc__gamma=1 ........................................
[CV] svc__C=500, svc__gamma=0.1, score=0.9094650205761317, total= 13.6s
[CV] svc__C=500, svc__gamma=1 ........................................
[CV] svc__C=500, svc__gamma=0.1, score=0.9172904191616766, total= 14.4s
[CV] svc__C=750, svc__gamma=0.0005 ...................................
[CV] svc__C=500, svc__gamma=0.1, score=0.9131736526946108, total= 13.3s
[CV] svc__C=500, svc__gamma=1, score=0.9386457164234941, total= 11.5s
[CV] svc__C=750, svc__gamma=0.0005 ...................................
[CV] svc__C=750, svc__gamma=0.0005 ...................................
[CV] svc__C=500, svc__gamma=0.1, score=0.9078996630475478, total= 13.6s
[CV] svc__C=750, svc__gamma=0.0005 ...................................
[CV] svc__C=500, svc__gamma=1, score=0.9143284698840254, total= 17.6s
[CV] svc__C=750, svc__gamma=0.0005 ...................................
[CV] svc__C=500, svc__gamma=1, score=0.9210329341317365, total= 16.6s
[CV] svc__C=750, svc__gamma=0.001 ....................................
[CV] svc__C=500, svc__gamma=1, score=0.9161676646706587, total= 15.5s
[CV] svc__C=750, svc__gamma=0.001 ....................................
[CV] svc__C=500, svc__gamma=1, score=0.9071508798202921, total= 16.6s
[CV] svc__C=750, svc__gamma=0.001 ....................................
[CV] svc__C=750, svc__gamma=0.0005, score=0.9210624766180322, total= 10.1s
[CV] svc__C=750, svc__gamma=0.001 ....................................
[CV] svc__C=750, svc__gamma=0.0005, score=0.8720538720538721, total= 14.5s
[CV] svc__C=750, svc__gamma=0.001 ....................................
[CV] svc__C=750, svc__gamma=0.0005, score=0.8802395209580839, total= 14.6s
[CV] svc__C=750, svc__gamma=0.01 .....................................
[CV] svc__C=750, svc__gamma=0.001, score=0.9285447063224841, total= 10.0s
[CV] svc__C=750, svc__gamma=0.01 .....................................
[CV] ....... svc__C=750, svc__gamma=0.0005, score=0.875, total= 14.9s
[CV] svc__C=750, svc__gamma=0.01 .....................................
[CV] svc__C=750, svc__gamma=0.001, score=0.8787878787878788, total= 13.2s
[CV] svc__C=750, svc__gamma=0.01 .....................................
[CV] svc__C=750, svc__gamma=0.0005, score=0.8715836765256458, total= 14.2s
[CV] svc__C=750, svc__gamma=0.01 .....................................
[CV] svc__C=750, svc__gamma=0.001, score=0.8914670658682635, total= 12.8s
[CV] svc__C=750, svc__gamma=0.1 ......................................
[CV] svc__C=750, svc__gamma=0.01, score=0.9438832772166106, total= 8.3s
[CV] svc__C=750, svc__gamma=0.1 ......................................
[CV] svc__C=750, svc__gamma=0.001, score=0.8851047904191617, total= 13.9s
[CV] svc__C=750, svc__gamma=0.1 ......................................
[CV] svc__C=750, svc__gamma=0.001, score=0.8809434668663422, total= 13.1s
[CV] svc__C=750, svc__gamma=0.1 ......................................
[CV] svc__C=750, svc__gamma=0.01, score=0.9083426861204639, total= 12.9s
[CV] svc__C=750, svc__gamma=0.1 ......................................
[CV] svc__C=750, svc__gamma=0.01, score=0.9202844311377245, total= 13.8s
[CV] svc__C=750, svc__gamma=1 ........................................
[CV] svc__C=750, svc__gamma=0.01, score=0.9157934131736527, total= 14.0s
[CV] svc__C=750, svc__gamma=0.1, score=0.9479985035540591, total= 8.9s
[CV] svc__C=750, svc__gamma=1 ........................................
[CV] svc__C=750, svc__gamma=1 ........................................
[CV] svc__C=750, svc__gamma=0.01, score=0.909771621115687, total= 13.9s
[CV] svc__C=750, svc__gamma=1 ........................................
[CV] svc__C=750, svc__gamma=0.1, score=0.9135802469135802, total= 14.0s
[CV] svc__C=750, svc__gamma=1 ........................................
[CV] svc__C=750, svc__gamma=0.1, score=0.9217814371257484, total= 13.9s
[CV] svc__C=750, svc__gamma=0.1, score=0.9157934131736527, total= 15.2s
[CV] svc__C=750, svc__gamma=0.1, score=0.9112691875701985, total= 14.1s
[CV] svc__C=750, svc__gamma=1, score=0.9349046015712682, total= 11.3s
[CV] svc__C=750, svc__gamma=1, score=0.9165731387953611, total= 16.8s
[CV] svc__C=750, svc__gamma=1, score=0.9127994011976048, total= 14.1s
[CV] svc__C=750, svc__gamma=1, score=0.9225299401197605, total= 15.6s
[CV] svc__C=750, svc__gamma=1, score=0.9127667540247099, total= 12.5s
[Parallel(n_jobs=-1)]: Done 125 out of 125 | elapsed: 5.4min finished
GridSearchCV(cv=5, error_score='raise',
estimator=Pipeline(memory=None,
steps=[('categoricaltransformer', CategoricalTransformer(columns=['favorite', 'interested', 'status', 'property_type', 'sale_type', 'source', 'state'])), ('dummyencoder', DummyEncoder()), ('imputer', Imputer(axis=0, copy=True, missing_values='NaN', strategy='median', verbose=0)), ('standardscaler', ...f',
max_iter=-1, probability=False, random_state=42, shrinking=True,
tol=0.001, verbose=False))]),
fit_params=None, iid=True, n_jobs=-1,
param_grid={'svc__C': [1, 10, 100, 500, 750], 'svc__gamma': [0.0005, 0.001, 0.01, 0.1, 1]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=3)
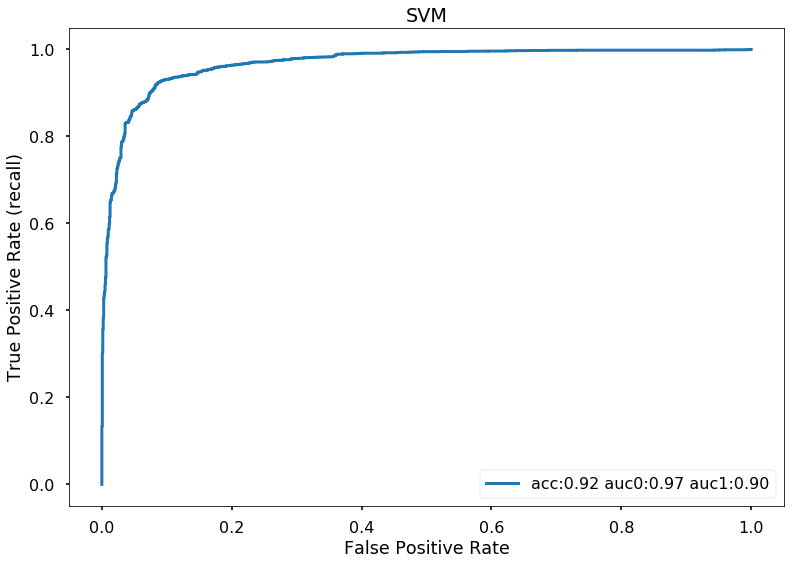
roc_auc_score(y_test, svmgrid.predict(X_test))
0.90180396517871109
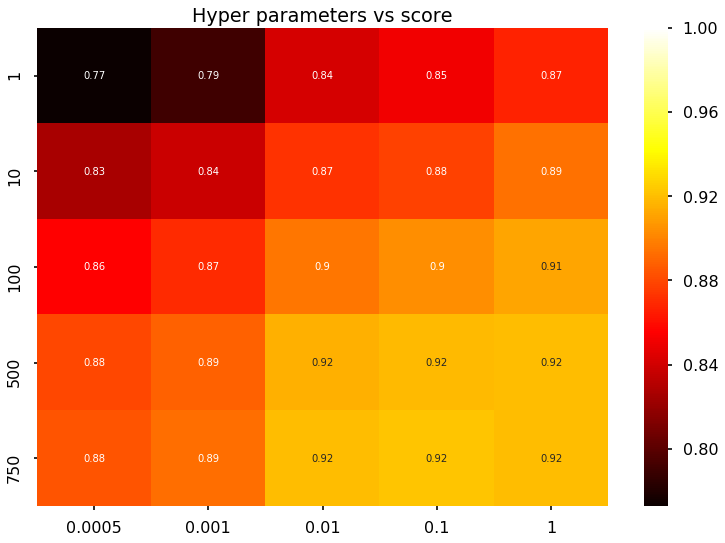
scores = svmgrid.cv_results_['mean_test_score'].reshape(5,5)
sns.heatmap(scores, vmax=1, xticklabels=param_grid['svc__gamma'], yticklabels=param_grid['svc__C'], cmap='hot', annot=True)
plt.title('Hyper parameters vs score')
plt.show()
plot_roc(svmgrid, X_test, y_test)
plt.title('SVM')
Text(0.5,1,'SVM')
Adaboost
from sklearn.ensemble import AdaBoostClassifier
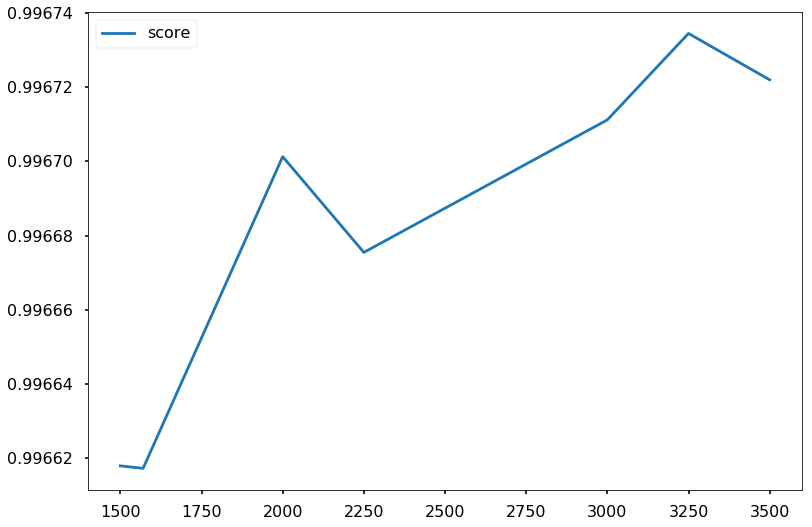
n_estimators = [ 1500, 1570, 2000, 2250, 3000, 3250, 3500]
param_grid = {'adaboostclassifier__n_estimators': n_estimators}
abpipe = make_pipeline(CategoricalTransformer(columns=cat_cols), DummyEncoder(), Imputer(strategy='median'), StandardScaler(),
AdaBoostClassifier())
abgrid = GridSearchCV(abpipe, param_grid, cv=5, n_jobs=-1, verbose=3, scoring=roc_auc_scorer)
abgrid.fit(X_train, y_train)
Fitting 5 folds for each of 7 candidates, totalling 35 fits
[CV] adaboostclassifier__n_estimators=1500 ...........................
[CV] adaboostclassifier__n_estimators=1500 ...........................
[CV] adaboostclassifier__n_estimators=1500 ...........................
[CV] adaboostclassifier__n_estimators=1500 ...........................
[CV] adaboostclassifier__n_estimators=1500 ...........................
[CV] adaboostclassifier__n_estimators=1570 ...........................
[CV] adaboostclassifier__n_estimators=1570 ...........................
[CV] adaboostclassifier__n_estimators=1570 ...........................
[CV] adaboostclassifier__n_estimators=1500, score=0.997032827451858, total= 20.4s
[CV] adaboostclassifier__n_estimators=1570 ...........................
[CV] adaboostclassifier__n_estimators=1500, score=0.996398639757171, total= 20.4s
[CV] adaboostclassifier__n_estimators=1500, score=0.9964454477248496, total= 20.5s
[CV] adaboostclassifier__n_estimators=1570 ...........................
[CV] adaboostclassifier__n_estimators=2000 ...........................
[CV] adaboostclassifier__n_estimators=1500, score=0.9957317073170731, total= 20.5s
[CV] adaboostclassifier__n_estimators=2000 ...........................
[CV] adaboostclassifier__n_estimators=1500, score=0.9974806405731442, total= 20.7s
[CV] adaboostclassifier__n_estimators=2000 ...........................
[CV] adaboostclassifier__n_estimators=1570, score=0.9970124254669422, total= 21.3s
[CV] adaboostclassifier__n_estimators=2000 ...........................
[CV] adaboostclassifier__n_estimators=1570, score=0.99648032853777, total= 21.4s
[CV] adaboostclassifier__n_estimators=2000 ...........................
[CV] adaboostclassifier__n_estimators=1570, score=0.9974924932834642, total= 21.7s
[CV] adaboostclassifier__n_estimators=2250 ...........................
[CV] adaboostclassifier__n_estimators=1570, score=0.9963485338755317, total= 22.4s
[CV] adaboostclassifier__n_estimators=2250 ...........................
[CV] adaboostclassifier__n_estimators=1570, score=0.9957521203181793, total= 22.6s
[CV] adaboostclassifier__n_estimators=2250 ...........................
[CV] adaboostclassifier__n_estimators=2000, score=0.9971358245692549, total= 27.9s
[CV] adaboostclassifier__n_estimators=2250 ...........................
[CV] adaboostclassifier__n_estimators=2000, score=0.9965517354849749, total= 28.1s
[CV] adaboostclassifier__n_estimators=2250 ...........................
[CV] adaboostclassifier__n_estimators=2000, score=0.9976037770636885, total= 28.7s
[CV] adaboostclassifier__n_estimators=3000 ...........................
[CV] adaboostclassifier__n_estimators=2000, score=0.996344578148034, total= 28.6s
[CV] adaboostclassifier__n_estimators=3000 ...........................
[CV] adaboostclassifier__n_estimators=2000, score=0.9958703181794236, total= 29.0s
[CV] adaboostclassifier__n_estimators=3000 ...........................
[CV] adaboostclassifier__n_estimators=2250, score=0.9965122477722349, total= 32.4s
[CV] adaboostclassifier__n_estimators=3000 ...........................
[Parallel(n_jobs=-1)]: Done 16 tasks | elapsed: 1.1min
[CV] adaboostclassifier__n_estimators=2250, score=0.9971371408263462, total= 31.8s
[CV] adaboostclassifier__n_estimators=3000 ...........................
[CV] adaboostclassifier__n_estimators=2250, score=0.9975270636885634, total= 32.3s
[CV] adaboostclassifier__n_estimators=3250 ...........................
[CV] adaboostclassifier__n_estimators=2250, score=0.9962773307805706, total= 31.8s
[CV] adaboostclassifier__n_estimators=3250 ...........................
[CV] adaboostclassifier__n_estimators=2250, score=0.9959233261339093, total= 32.4s
[CV] adaboostclassifier__n_estimators=3250 ...........................
[CV] adaboostclassifier__n_estimators=3000, score=0.9971509615258052, total= 42.0s
[CV] adaboostclassifier__n_estimators=3250 ...........................
[CV] adaboostclassifier__n_estimators=3000, score=0.9966264330749082, total= 42.8s
[CV] adaboostclassifier__n_estimators=3250 ...........................
[CV] adaboostclassifier__n_estimators=3000, score=0.9975313438339567, total= 42.7s
[CV] adaboostclassifier__n_estimators=3500 ...........................
[CV] adaboostclassifier__n_estimators=3000, score=0.9959667860717484, total= 43.3s
[CV] adaboostclassifier__n_estimators=3500 ...........................
[CV] adaboostclassifier__n_estimators=3000, score=0.9962802975761939, total= 43.1s
[CV] adaboostclassifier__n_estimators=3500 ...........................
[CV] adaboostclassifier__n_estimators=3250, score=0.996706066628934, total= 46.5s
[CV] adaboostclassifier__n_estimators=3500 ...........................
[CV] adaboostclassifier__n_estimators=3250, score=0.9972095349663697, total= 46.3s
[CV] adaboostclassifier__n_estimators=3500 ...........................
[CV] adaboostclassifier__n_estimators=3250, score=0.9975178449138703, total= 48.1s
[CV] adaboostclassifier__n_estimators=3250, score=0.995986540588948, total= 47.2s
[CV] adaboostclassifier__n_estimators=3250, score=0.9962522778397508, total= 47.1s
[CV] adaboostclassifier__n_estimators=3500, score=0.9966935621865662, total= 50.6s
[CV] adaboostclassifier__n_estimators=3500, score=0.997175312281995, total= 49.3s
[Parallel(n_jobs=-1)]: Done 32 out of 35 | elapsed: 2.8min remaining: 15.9s
[CV] adaboostclassifier__n_estimators=3500, score=0.9975040167518305, total= 40.4s
[CV] adaboostclassifier__n_estimators=3500, score=0.9959615182004952, total= 39.1s
[CV] adaboostclassifier__n_estimators=3500, score=0.9962753529168216, total= 36.8s
[Parallel(n_jobs=-1)]: Done 35 out of 35 | elapsed: 3.2min finished
GridSearchCV(cv=5, error_score='raise',
estimator=Pipeline(memory=None,
steps=[('categoricaltransformer', CategoricalTransformer(columns=['favorite', 'interested', 'status', 'property_type', 'sale_type', 'source', 'state'])), ('dummyencoder', DummyEncoder()), ('imputer', Imputer(axis=0, copy=True, missing_values='NaN', strategy='median', verbose=0)), ('standardscaler', ...m='SAMME.R', base_estimator=None,
learning_rate=1.0, n_estimators=50, random_state=None))]),
fit_params=None, iid=True, n_jobs=-1,
param_grid={'adaboostclassifier__n_estimators': [1500, 1570, 2000, 2250, 3000, 3250, 3500]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=make_scorer(roc_auc_score, needs_threshold=True), verbose=3)
pd.DataFrame({'score':abgrid.cv_results_['mean_test_score']}, index=abgrid.cv_results_['param_adaboostclassifier__n_estimators']).plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f1cdee9ac50>
roc_auc_score(y_test, abgrid.predict(X_test))
0.96757739512200769
abgrid.best_estimator_, abgrid.best_params_
(Pipeline(memory=None,
steps=[('categoricaltransformer', CategoricalTransformer(columns=['favorite', 'interested', 'status', 'property_type', 'sale_type', 'source', 'state'])), ('dummyencoder', DummyEncoder()), ('imputer', Imputer(axis=0, copy=True, missing_values='NaN', strategy='median', verbose=0)), ('standardscaler', ...'SAMME.R', base_estimator=None,
learning_rate=1.0, n_estimators=3250, random_state=None))]),
{'adaboostclassifier__n_estimators': 3250})