Hyperparameter Tuning & ML Pipelines¶
About me:¶
I am Atul Saurav (@twtAtul),
- Lead Genworth Financials' Data Engineering Team
- MS in Decison Analytics, VCU DAPT class of 2019
- Passionate about learning, data and everything around it
You can also find me on LinkedIn
What is this talk about?¶
- Building Machine Learning Models
- Python specific
- scikit-learn based models
What is this talk not about?¶
- Data Cleansing
- Feature Engineering
- Deep Learning
- Other exciting stuff that is difficult to cover in 1 meetup!
All models are wrong but some are useful¶
Box, G. E. P. (1979), "Robustness in the strategy of scientific model building", in Launer, R. L.; Wilkinson, G. N., Robustness in Statistics, Academic Press, pp. 201–236.
Reality is complex -¶
too many factors influence outcome
factors difficult to measure accurately and objectively
not all factors may be known
Approach¶
- Use toy datasets for illustration and visualization
- Use real dataset for demonstrating application efficacy
Scikit-learn API Overview¶
- All methods are implemented as estimators
- All estimators have a
.fit()method - All supervised estimators have
.predict()method - All unsupervised estimators have
.transform()method
| ``model.predict`` | ``model.transform`` |
|---|---|
| Classification | Preprocessing |
| Regression | Dimensionality Reduction |
| Clustering | Feature Extraction |
| Feature Selection |
Usual High Level Flow¶
In [ ]:
from sklearn.family import SomeModel
myModel = SomeModel()
myModel.fit(X_train,y_train)
# supervised
myModel.predict(X_test)
myModel.score(X_test, y_test)
## unsupervised
myModel.transform(X_train)
Problem Statement¶
- Classify data into 2 groups based on already observed groupings
- Using house price data, predict if the price of the given house will be >= 500K
Binary Classification Problem¶
Toy Example¶
In [2]:
from sklearn.datasets import make_blobs
scaled_X, scaled_y = make_blobs(centers=2, random_state=0)
scaled_X[:,0] = 10* scaled_X[:,0] + 3
X, y = make_blobs(centers=2, random_state=0)
print('X ~ n_samples x n_features:', X.shape)
print('y ~ n_samples:', y.shape)
Visualize Data¶
In [3]:
fig, (ax0, ax1) = plt.subplots(nrows=1, ncols=2, figsize=(10,5))
ax0.scatter(X[y == 0, 0], X[y == 0, 1], c='blue', s=40, label='0')
ax0.scatter(X[y == 1, 0], X[y == 1, 1], c='red', s=40, label='1', marker='s')
ax0.set_xlabel('first feature')
ax0.set_ylabel('second feature')
ax1.scatter(scaled_X[scaled_y == 0, 0], scaled_X[scaled_y == 0, 1], c='blue', s=40, label='0')
ax1.scatter(scaled_X[scaled_y == 1, 0], scaled_X[scaled_y == 1, 1], c='red', s=40, label='1', marker='s')
ax1.set_xlabel('first feature')
Out[3]:

Create Training and Test Set¶
Training Set - Data used to train the model
Test Set - Data held out in the very beginning for testing model performance. This data should not be touched until final scoring
In [4]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25,
random_state=1234,
stratify=y)
scaled_X_train, scaled_X_test, \
scaled_y_train, scaled_y_test = train_test_split(scaled_X,
scaled_y,
test_size=0.25,
random_state=1234,
stratify=y)
In [5]:
X_train.shape
Out[5]:
In [6]:
y_train.shape
Out[6]:
Train a Nearest Neighbor Classifier - 1 Neighbor¶
Overfit!!
In [7]:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
Out[7]:
In [8]:
scaled_knn = KNeighborsClassifier(n_neighbors=1)
scaled_knn.fit(scaled_X_train, scaled_y_train)
Out[8]:
Comapre Model Performance¶
In [9]:
knn.score(X_test, y_test)
Out[9]:
In [10]:
scaled_knn.score(scaled_X_test, scaled_y_test)
Out[10]:
Visualize Model - regular¶
In [11]:
from figures import plot_2d_separator
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='blue', s=40, label='0')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(knn, X)
_ = plt.legend()

Visualize Model - scaled¶
In [12]:
from figures import plot_2d_separator
plt.scatter(scaled_X[scaled_y == 0, 0], scaled_X[scaled_y == 0, 1], c='blue', s=40, label='0')
plt.scatter(scaled_X[scaled_y == 1, 0], scaled_X[scaled_y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(scaled_knn, scaled_X)
_ = plt.legend()

Train Nearest Neighbor Classifier - 10 neighbors¶
In [13]:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
Out[13]:
In [14]:
scaled_knn = KNeighborsClassifier(n_neighbors=10)
scaled_knn.fit(scaled_X_train, scaled_y_train)
Out[14]:
Comapre Model Performance¶
In [15]:
knn.score(X_test, y_test)
Out[15]:
In [16]:
scaled_knn.score(scaled_X_test, scaled_y_test)
Out[16]:
Visualize Model - regular¶
In [17]:
from figures import plot_2d_separator
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='blue', s=40, label='0')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(knn, X)
_ = plt.legend()

Visualize Model - scaled¶
In [18]:
from figures import plot_2d_separator
plt.scatter(scaled_X[scaled_y == 0, 0], scaled_X[scaled_y == 0, 1], c='blue', s=40, label='0')
plt.scatter(scaled_X[scaled_y == 1, 0], scaled_X[scaled_y == 1, 1], c='red', s=40, label='1', marker='s')
plt.xlabel("first feature")
plt.ylabel("second feature")
plot_2d_separator(scaled_knn, scaled_X)
_ = plt.legend()

Tunning # of Neighbors¶
In [19]:
train_scores = []
test_scores = []
n_neighbors = range(1,28)
for neighbor in n_neighbors:
knn = KNeighborsClassifier(n_neighbors=neighbor)
knn.fit(X_train, y_train)
train_scores.append(knn.score(X_train, y_train))
test_scores.append(knn.score(X_test, y_test))
plt.plot(n_neighbors, train_scores, label='train')
plt.plot(n_neighbors, test_scores, label='test')
plt.ylabel('Accuracy')
plt.xlabel('# of neighbors')
plt.legend();plt.show()

But Wait!! Is that Hyperparameter Tuning?¶
No¶
Hyperparameter tuning is part of Model building and Test Data should not be used in model build¶
Hyperparameter Tuning should be performed using Validation Set - a subset of training set¶
Real Life Example - Housing Data¶
In [22]:
data = pd.read_csv('new_train.csv')
data.columns = [ x.lower().replace('.','_') for x in data.columns]
data.head().T
Out[22]:
Some Observations¶
In [23]:
data.info()
What's different?¶
- Not all features are numeric - Categorical Variables
- Lot of missing data points
In [24]:
del(data['sold_date'])
del(data['next_open_house_start_time'])
del(data['next_open_house_end_time'])
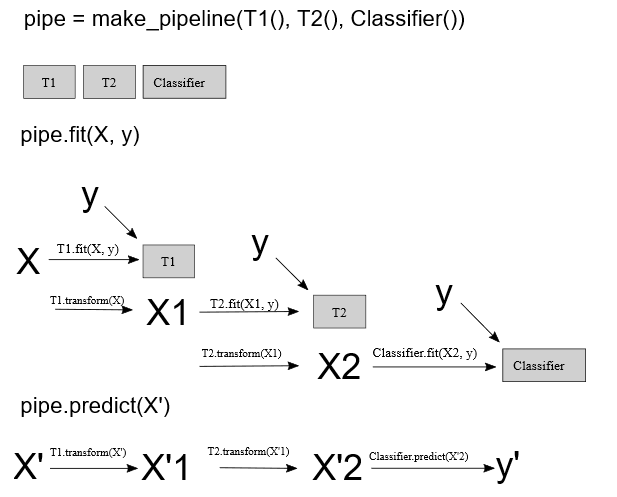
More on Pipelines and GridSearchCV¶
- also known as meta-estimators in scikit-learn
- they inherit the properties of the last estimator used
- pipeline is used to chain multiple estimator into one pipe so output of one flows as input of next
- GridSearchCV is used to search on a hyperparameter grid the model with the best score
Making ML Pipelines¶
In [ ]:
from sklearn.pipeline import make_pipeline
make_pipeline( CategoricalTransformer(columns=cat_cols), DummyClassifier("most_frequent"))
Back to real life housing classification problem¶
Which features have less than 20% missing values?¶
In [25]:
d = pd.DataFrame(null_pct(data), index=['null_pct']).T.sort_values('null_pct')
d[(d.null_pct< .2 )]
Out[25]:
Set features to work with¶
In [26]:
new_features = ['id', 'favorite', 'interested', 'latitude', 'longitude', 'status', 'property_type', 'sale_type', 'source',
'state', 'beds', 'baths', 'year_built', 'x__square_feet', 'square_feet', 'target']
sub_data = data[new_features]
sub_data.head(3)
Out[26]:
Set model Inputs¶
In [32]:
X = sub_data[['favorite', 'interested', 'latitude', 'longitude', 'status', 'property_type', 'sale_type',
'source', 'state', 'beds', 'baths', 'year_built', 'x__square_feet', 'square_feet']]
y = sub_data.target
In [33]:
cat_cols = ['favorite', 'interested', 'status', 'property_type', 'sale_type', 'source', 'state']
Establish base case for prediction¶
In [34]:
dummy_pipe = make_pipeline( CategoricalTransformer(columns=cat_cols), DummyEncoder(), DummyClassifier("most_frequent"))
cross_val_score(dummy_pipe, X, y)
Out[34]:
Create training and test set¶
In [35]:
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state=42 )
Support Vector Machine¶
In [36]:
Cs = [ 1, 10, 100, 500, 750]
gammas = [0.0005, 0.001, 0.01, .1, 1]
param_grid = {'svc__C': Cs, 'svc__gamma' : gammas}
In [37]:
svc_pipe = make_pipeline( CategoricalTransformer(columns=cat_cols), DummyEncoder(), Imputer(strategy='median'), StandardScaler(), SVC(random_state=42) )
In [38]:
svmgrid = GridSearchCV(svc_pipe, param_grid, cv=5, n_jobs=-1, verbose=3)#, scoring=roc_auc_scorer)
svmgrid.fit(X_train, y_train)
Out[38]:
In [39]:
roc_auc_score(y_test, svmgrid.predict(X_test))
Out[39]:
In [40]:
scores = svmgrid.cv_results_['mean_test_score'].reshape(5,5)
sns.heatmap(scores, vmax=1, xticklabels=param_grid['svc__gamma'], yticklabels=param_grid['svc__C'], cmap='hot', annot=True)
plt.title('Hyper parameters vs score')
plt.show()

Adaboost¶
In [42]:
from sklearn.ensemble import AdaBoostClassifier
In [43]:
n_estimators = [ 1500, 1570, 2000, 2250, 3000, 3250, 3500]
param_grid = {'adaboostclassifier__n_estimators': n_estimators}
In [44]:
abpipe = make_pipeline(CategoricalTransformer(columns=cat_cols), DummyEncoder(), Imputer(strategy='median'), StandardScaler(),
AdaBoostClassifier())
In [45]:
abgrid = GridSearchCV(abpipe, param_grid, cv=5, n_jobs=-1, verbose=3, scoring=roc_auc_scorer)
abgrid.fit(X_train, y_train)
Out[45]:
In [46]:
pd.DataFrame({'score':abgrid.cv_results_['mean_test_score']}, index=abgrid.cv_results_['param_adaboostclassifier__n_estimators']).plot()
Out[46]:

In [47]:
roc_auc_score(y_test, abgrid.predict(X_test))
Out[47]:
In [48]:
abgrid.best_estimator_, abgrid.best_params_
Out[48]: